
basic introduction
對資料進行分析,基本上過程大致如以下
- 資料收集
- 使用工具分析資料
- 可視化分析(作圖)
- 建模
- 解釋結果
網路上資料收集方式有很多,從簡便到麻煩依序大致如以下,如果遇到需要取資料時,可以條列式的篩選找到合適方法.
API < 開發者工具的xhr/fetch解析 < bs4解析html中css跟tag < selenium解析html跟點擊
基本上當然是先從簡單開始 try,假設今天已經取到所需的資料了,它可能是 csv,Json 等格式,接著分析資料步驟就會是pandas上場的時候.
分析資料:常見流程有 數據準備、選取、過濾、聚合、分組、排序、合併、填充缺失值,另外因為他的資料結構也有跟 python 的繪圖工具做整合,也可以搭配使用,常用的繪圖工具如以下.
- Plotly 和 Bokeh 是基於 JavaScript 的交互式圖表,也支援其他語言 ex.Python,可以創建互動性更強的圖表,如滑塊、下拉選單等。
- Altair 是基於 Vega-Lite 的 Python 套件,支持將數據轉換為交互式圖表,優點是語法較簡單。
- Seaborn 則是一個統計圖表套件,專注於統計繪圖,方便使用者進行常見的數據分析和繪圖操作。
- Matplotlib 是 Python 最早期的繪圖套件之一,功能強大,可以繪製各種圖表,包括條形圖、直方圖、散點圖等等,基本上 Seaborn 是建立在 Matplotlib 之上。
- Pyecharts 則是中國的一個開源圖表庫,提供了各種各樣的圖表,能夠繪製地圖、關係圖、熱力圖等多種圖表。
數據準備
以下數據是改過後的數據,會作為後面 demo 過程範例,基本上你想得到的數據格式 pandas 都支援了,md 檔,csv,dict,json...
pandas 主要數據結構有
Series:一維數據結構,類似於帶有標籤的一維數組,可以容納不同類型的數據。
DataFrame:二維數據結構,類似於一個二維數組或一個關聯數據庫表,每列可以有不同的數據類型。
Panel:三維數據結構,類似於一個由 DataFrame 對象組成的字典,可以用來表示由多個 DataFrame 對象組成的數據集。
最常會使用到的就是 DataFrame.
Python 物件轉 pandas dataframe
以下是把資料存成 dict in list 的型態
[{'name': 'TM-Zx-1040', 'filePath': '/AppliZxations/iMyFone LoZxkWiper.app/Zxontents/MaZxOS/fixiOSLib/FixOS', 'start_time': '2023-03-29 14:25:05', 'open_id': 'H-GOGO-20230329-00001'}, {'name': 'XD-Zx-1073', 'filePath': '\\DeviZxe\\HarddiskVolume3\\Program Files (x86)\\IObit\\AdvanZxed SystemZxare\\ASZxServiZxe.exe', 'start_time': '2023-04-18 02:38:40', 'open_id': 'H-GOGO-20230418-00001'}, {'name': 'XD-Zx-1073', 'filePath': '\\DeviZxe\\HarddiskVolume3\\Program Files (x86)\\IObit\\AdvanZxed SystemZxare\\ASZxServiZxe.exe', 'start_time': '2023-04-13 21:51:19', 'open_id': 'H-GOGO-20230413-00029'}, {'name': 'XD-Zx-1073', 'filePath': '\\DeviZxe\\HarddiskVolume3\\Program Files (x86)\\IObit\\AdvanZxed SystemZxare\\ASZxServiZxe.exe', 'start_time': '2023-04-10 22:13:29', 'open_id': 'H-GOGO-20230410-00053'}, {'name': 'XD-Zx-1073', 'filePath': '\\DeviZxe\\HarddiskVolume3\\Program Files (x86)\\IObit\\AdvanZxed SystemZxare\\ASZxServiZxe.exe', 'start_time': '2023-04-05 18:47:26', 'open_id': 'H-GOGO-20230405-00001'}, {'name': 'XD-Zx-1073', 'filePath': '\\DeviZxe\\HarddiskVolume3\\Program Files (x86)\\IObit\\AdvanZxed SystemZxare\\ASZxServiZxe.exe', 'start_time': '2023-04-03 21:04:38', 'open_id': 'H-GOGO-20230403-00002'}, {'name': 'XD-Zx-1073', 'filePath': '\\DeviZxe\\HarddiskVolume3\\Program Files (x86)\\IObit\\AdvanZxed SystemZxare\\ASZxServiZxe.exe', 'start_time': '2023-04-03 04:51:22', 'open_id': 'H-GOGO-20230403-00001'}, {'name': 'XD-Zx-1073', 'filePath': '\\DeviZxe\\HarddiskVolume3\\Program Files (x86)\\IObit\\AdvanZxed SystemZxare\\ASZxServiZxe.exe', 'start_time': '2023-04-01 22:42:13', 'open_id': 'H-GOGO-20230402-00002'}, {'name': 'XD-Zx-1073', 'filePath': '\\DeviZxe\\HarddiskVolume3\\Program Files (x86)\\IObit\\AdvanZxed SystemZxare\\ASZx.exe', 'start_time': '2023-04-01 23:58:44', 'open_id': 'H-GOGO-20230402-00001'}, {'name': 'XD-Zx-1073', 'filePath': '\\DeviZxe\\HarddiskVolume3\\Program Files (x86)\\IObit\\AdvanZxed SystemZxare\\ASZxServiZxe.exe', 'start_time': '2023-03-30 20:11:05', 'open_id': 'H-GOGO-20230330-00001'}, {'name': 'XD-Zx-1073', 'filePath': '\\DeviZxe\\HarddiskVolume3\\Program Files (x86)\\IObit\\AdvanZxed SystemZxare\\ASZxServiZxe.exe', 'start_time': '2023-03-29 21:15:40', 'open_id': 'H-GOGO-20230329-00002'}, {'name': 'XD-Zx-1073', 'filePath': '\\DeviZxe\\HarddiskVolume3\\Program Files (x86)\\IObit\\AdvanZxed SystemZxare\\ASZxServiZxe.exe', 'start_time': '2023-03-28 22:28:29', 'open_id': 'H-GOGO-20230328-00001'}, {'name': 'XD-SAS-1045', 'filePath': '\\DeviZxe\\HarddiskVolume5\\Users\\miriam.lin\\AppData\\Roaming\\InsLogiZxZxfg\\PS\\PSDD\\9487.exe', 'start_time': '2023-04-17 18:04:27', 'open_id': 'H-GOGO-20230417-00027'}, {'name': 'XD-SAS-1073', 'filePath': '\\DeviZxe\\HarddiskVolume3\\Users\\DON\\Desktop\\NaviZxat Keygen PatZxh v5.6.0 DFoX.exe', 'start_time': '2023-04-18 11:17:21', 'open_id': 'H-GOGO-20230418-00004'}, {'name': 'XD-SAS-1073', 'filePath': '\\DeviZxe\\HarddiskVolume3\\Users\\DON\\Desktop\\NaviZxat Keygen PatZxh v5.6.0 DFoX.exe', 'start_time': '2023-04-18 11:17:23', 'open_id': 'H-GOGO-20230418-00003'}, {'name': 'XD-SAS-1073', 'filePath': '\\DeviZxe\\HarddiskVolume3\\Users\\DON\\Desktop\\NaviZxat Keygen PatZxh v5.6.0 DFoX.exe', 'start_time': '2023-04-18 11:17:01', 'open_id': nan}]
把 dict in list 轉成 dataframe,dict 的 key 會對應到欄位名稱,value 對應欄位資料內容
df=pd.DataFrame(json_data)
print(df)
## data
name filePath start_time open_id
0 TM-Zx-1040 /AppliZxations/iMyFone LoZxkWiper.app/Zxontent... 2023-03-29 14:25:05 H-GOGO-20230329-00001
1 XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-04-18 02:38:40 H-GOGO-20230418-00001
2 XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-04-13 21:51:19 H-GOGO-20230413-00029
3 XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-04-10 22:13:29 H-GOGO-20230410-00053
......
CSV 轉 pandas dataframe
以下是 CSV 格式
name,filePath,start_time,open_id
TM-Zx-1040,/AppliZxations/iMyFone LoZxkWiper.app/Zxontents/MaZxOS/fixiOSLib/FixOS,2023-03-29 14:25:05,H-GOGO-20230329-00001
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-04-18 02:38:40,H-GOGO-20230418-00001
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-04-13 21:51:19,H-GOGO-20230413-00029
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-04-10 22:13:29,H-GOGO-20230410-00053
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-04-05 18:47:26,H-GOGO-20230405-00001
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-04-03 21:04:38,H-GOGO-20230403-00002
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-04-03 04:51:22,H-GOGO-20230403-00001
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-04-01 22:42:13,H-GOGO-20230402-00002
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZx.exe,2023-04-01 23:58:44,H-GOGO-20230402-00001
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-03-30 20:11:05,H-GOGO-20230330-00001
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-03-29 21:15:40,H-GOGO-20230329-00002
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-03-28 22:28:29,H-GOGO-20230328-00001
XD-SAS-1045,\DeviZxe\HarddiskVolume5\Users\miriam.lin\AppData\Roaming\InsLogiZxZxfg\PS\PSDD\9487.exe,2023-04-17 18:04:27,H-GOGO-20230417-00027
XD-SAS-1073,\DeviZxe\HarddiskVolume3\Users\DON\Desktop\NaviZxat Keygen PatZxh v5.6.0 DFoX.exe,2023-04-18 11:17:21,H-GOGO-20230418-00004
XD-SAS-1073,\DeviZxe\HarddiskVolume3\Users\DON\Desktop\NaviZxat Keygen PatZxh v5.6.0 DFoX.exe,2023-04-18 11:17:23,H-GOGO-20230418-00003
XD-SAS-1073,\DeviZxe\HarddiskVolume3\Users\DON\Desktop\NaviZxat Keygen PatZxh v5.6.0 DFoX.exe,2023-04-18 11:17:01,
把 csv 讀成 dataframe
df = pd.read_csv('XXX.csv')
有了 df 以後可以用基本的屬性去了解他的 index,column name, 表總長度等
# 確認 DataFrame 的 index
print(df.index) #RangeIndex(start=0, stop=16, step=1)
# 確認 DataFrame 的欄位名稱
print(df.columns) #Index(['name', 'filePath', 'start_time', 'open_id'], dtype='object')
# 確認 DataFrame 的總長度
print(len(df)) #16
#讀前十行
print(df.head(10))
#列出各欄位型態
print(df.dtypes)
name object
filePath object
start_time object
open_id object
dtype: object
print(df.shape) #(16, 4) 顯示 (16, 4) 表示 df 有 16 列(row) 和 4 行(column)。
#括每個 column 的名稱、非空值的數量、數值型別、以及佔用的記憶體大小等等。
print(df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 16 entries, 0 to 15
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 16 non-null object
1 filePath 16 non-null object
2 start_time 16 non-null object
3 open_id 15 non-null object
dtypes: object(4)
memory usage: 640.0+ bytes
# 欄位的總數、平均值、標準差、最小值、25% 分位數、50% 分位數、75% 分位數、最大值等資
print(df.describe())
name filePath start_time open_id
count 16 16 16 15
unique 4 5 16 15
top XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-03-29 14:25:05 H-GOGO-20230329-00001
freq 11 10 1 1
小結
常用的是 df.shape,df.index,df.dtypes,df.info(),df.columns,還有 len(df)等,去描述 df 的欄位的型態.
df.shape: 返回 DataFrame 的行數和列數,以元組形式返回 (rows, columns)。
df.index: 返回 DataFrame 的索引 (Index)。
df.columns: 返回 DataFrame 的列名。
df.dtypes: 返回 DataFrame 每個列的數據類型。
df.info(): 返回 DataFrame 的簡要摘要,包括每個列的名稱、非空值的數量、每個列的數據類型、索引的數量、記憶體使用量等等。
len(df): 返回 DataFrame 的行數。
選取
- 使用隱性索引來選取各行資料
# 列出0~10行
print(df[0:11])
- iloc 切片 :iloc 是使用隱性索引來選取資料,東西在 [] 裡面,索引值 0 是行,索引值 1 是列。 可以使用 : 選取一定範圍的列或行。
df.iloc[1:4,0:3]: 選取 1~3 行,0~2 列
df.iloc[[0, 1]]:使用隱式索引選取第 0 和第 1 行。
df.iloc[[0, 2], [1, 3]]:使用隱式索引選取第 0 和第 2 行以及第 1 和第 3 列。
df.iloc[:,0:7]:選取所有行的前 7 列。
df.iloc[10:30,2:3]=None:將第 10 到第 29 行的第 2 列值設為 None。
df.iloc[10:30,:]=None: 第 10 ~29 行 所有列換成 None
df.iloc[10:30,:-2]=None: 第 10 ~29 行 除了倒數兩列之外的列換成 None
- loc 遮罩:可以用切片或者布林向量選值,這邊 index 是顯示索引,一定要有對應的 index 名稱. 有用範圍就用切片:,用切片不用中括號.
print(df.loc[[1, 3], ["name", "start_time"]]) # 取出 index 為 1, 3 的 name 和 start_time 兩個 column
print(df.loc[1:3, ["name", "start_time"]]) # 取出 index 為 1, 2, 3 的 name 和 start_time 兩個 column
print(df.loc[1:3, "name":"start_time"]) # 取出 index 為 1, 2, 3 的 name 到 start_time 三個 column
- 倒放 df.T
print(df.T)
0 ... 15
name TM-Zx-1040 ... XD-SAS-1073
filePath /AppliZxations/iMyFone LoZxkWiper.app/Zxontent... ... \DeviZxe\HarddiskVolume3\Users\DON\Desktop\Nav...
start_time 2023-03-29 14:25:05 ... 2023-04-18 11:17:01
open_id H-GOGO-20230329-00001 ... NaN
print(df.T.index) #Index(['name', 'filePath', 'start_time', 'open_id'], dtype='object')
- 直接拿某欄位值 at[],使用 label (index & column name) 取值, .iat[]. (.at['a','b'] 索引為 a 列名為 b), df.iat[3, 2] 只能用隱性索引 (integer) 取值,這邊是取第 4 行第 3 列(2023-04-10 22:13:29).
過濾
過濾出 name 欄位字有 XD-Zx 字樣者 使用 query 方式找:
df.query("name.str.contains('XD-Zx')")
使用 bool 布林選擇的方式:
df[df['name'].str.contains('XD-Zx')]
分組聚合
在 Pandas 中,聚合指的是將資料集按照某些條件分組,然後對分組後的資料集進行計算的過程。常見的聚合函數有:sum(求和)、mean(求平均)、median(求中位數)、min(求最小值)、max(求最大值)等等。
Pandas 中聚合的方法主要有兩種:groupby 和 pivot_table。
groupby 方法將資料集按照某些欄位進行分組,然後對分組後的資料進行聚合操作。例如,將資料集按照某一欄位進行分組,然後計算每個分組的平均值。
參考這篇文章對於 groupby 的講解,groupby 其實就是對資料進行分組,例如途中 company 有多個 C、A、B,這些行都會被聚集在一起,後續可以用 agg 或 transform 聚合操作,也可以透過 apply 使用自訂意函式處理資料.
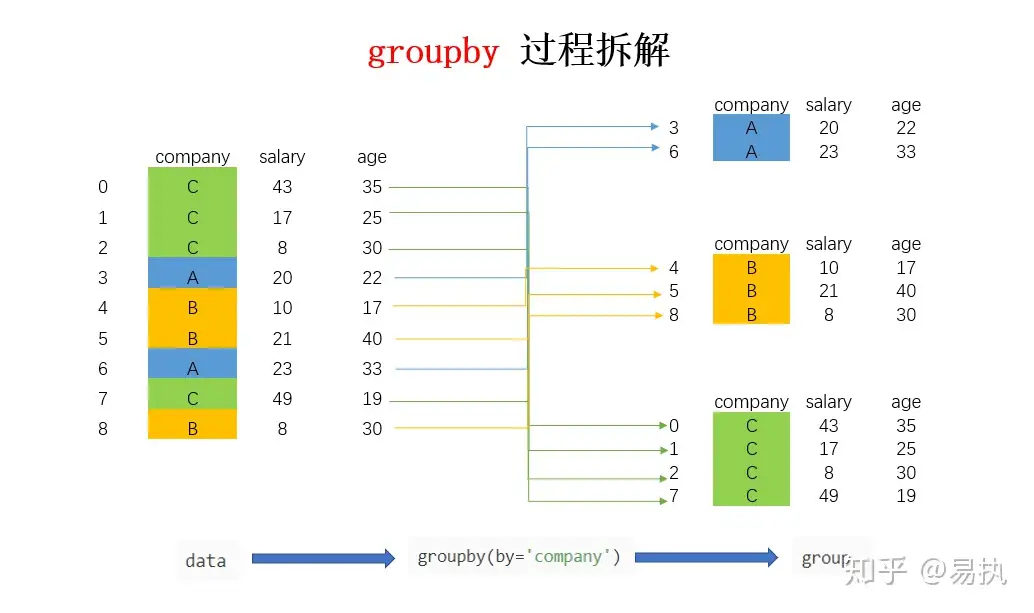
lab 1.使用 groupby 然後把重複的 name,filePath 併成一個,然後把 path 跟 name 輸出(答案很多,這邊寫幾個)
法ㄧ、透過以['name', 'filePath']分組,使用 agg 把欄位壓成一個(不壓會只有記憶體位置),然後把['name', 'filePath']拿會去當欄位
group_df=df.groupby(['name', 'filePath']).agg({'start_time': 'count'}).reset_index()
print(group_df)
name filePath start_time
0 TM-Zx-1040 /AppliZxations/iMyFone LoZxkWiper.app/Zxontent... 1
1 XD-SAS-1045 \DeviZxe\HarddiskVolume5\Users\miriam.lin\AppD... 1
2 XD-SAS-1073 \DeviZxe\HarddiskVolume3\Users\DON\Desktop\Nav... 3
3 XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 1
4 XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 10
# 打印表中每行資訊
for index, row in group_df.iterrows():
print(type(row)) #<class 'pandas.core.series.Series'>
print(row['filePath'],row['name'])
<class 'pandas.core.series.Series'>
/AppliZxations/iMyFone LoZxkWiper.app/Zxontents/MaZxOS/fixiOSLib/FixOS TM-Zx-1040
<class 'pandas.core.series.Series'>
\DeviZxe\HarddiskVolume5\Users\miriam.lin\AppData\Roaming\InsLogiZxZxfg\PS\PSDD\9487.exe XD-SAS-1045
<class 'pandas.core.series.Series'>
\DeviZxe\HarddiskVolume3\Users\DON\Desktop\NaviZxat Keygen PatZxh v5.6.0 DFoX.exe XD-SAS-1073
<class 'pandas.core.series.Series'>
\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZx.exe XD-Zx-1073
<class 'pandas.core.series.Series'>
\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe XD-Zx-1073
or
法二、這段程式碼會先用 groupby 方法按照 'name' 列進行分組,然後對 'filePath' 列進行聚合操作,使用 lambda 函數來將相同的 filePath 合併成一個字符串,並將字符串中的重複值去除。最後用 sort_index() 方法對結果進行排序,按照 'name' 列的字母順序排序。
接下來的 for 循環,對 df_join 中的每一行進行迭代,其中 index 是當前行的索引值,row 是當前行的 Series 對象。在循環體中,先打印出 index,然後打印出 row,發現 row 是一個 Series 對象,包含了當前行的所有列。
df_join=df.groupby('name').agg({'filePath': lambda x: '\n '.join(set(x))}).sort_index()
df_join.to_csv("test.csv")
結果
name,filePath
TM-Zx-1040,/AppliZxations/iMyFone LoZxkWiper.app/Zxontents/MaZxOS/fixiOSLib/FixOS
XD-SAS-1045,\DeviZxe\HarddiskVolume5\Users\miriam.lin\AppData\Roaming\InsLogiZxZxfg\PS\PSDD\9487.exe
XD-SAS-1073,\DeviZxe\HarddiskVolume3\Users\DON\Desktop\NaviZxat Keygen PatZxh v5.6.0 DFoX.exe
XD-Zx-1073,"\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe
\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZx.exe"
pivot_table 方法將資料集按照某些欄位進行分類,並根據另一欄位的值來計算匯總資料。例如,按照某一欄位進行分類,然後計算每組的平均值。
排序
主要有 sort_index 跟 sort_values,將表進行排序.
sort_values: 根據數據值對 DataFrame 或 Series 進行排序,預設是升序(也就是 ascending=True),將數值由低到高排列,常用參數 ascending,inplace. inplace=True 時會修改原本 df 並 return None.
sort_index: 根據索引對 DataFrame 或 Series 進行排序
sort_values:
print(df.sort_values(by="start_time").head(10))
name filePath start_time open_id
11 XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-03-28 22:28:29 H-GOGO-20230328-00001
0 TM-Zx-1040 /AppliZxations/iMyFone LoZxkWiper.app/Zxontent... 2023-03-29 14:25:05 H-GOGO-20230329-00001
10 XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-03-29 21:15:40 H-GOGO-20230329-00002
9 XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-03-30 20:11:05 H-GOGO-20230330-00001
......
sort_index: 先使用 inplace=True,很明顯可以看到 index 因為 sort_values 關係所以排序改了,變成 11,0,10,9 等. 這邊可以透過 sort_index 對此從排
# 用sort_values並帶參數inplace=True改排序
df.sort_values(by="start_time",inplace=True)
print(df)
name filePath start_time open_id
11 XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-03-28 22:28:29 H-GOGO-20230328-00001
0 TM-Zx-1040 /AppliZxations/iMyFone LoZxkWiper.app/Zxontent... 2023-03-29 14:25:05 H-GOGO-20230329-00001
10 XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-03-29 21:15:40 H-GOGO-20230329-00002
9 XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-03-30 20:11:05 H-GOGO-20230330-00001
....
# 變回來
print(df.sort_index())
name filePath start_time open_id
0 TM-Zx-1040 /AppliZxations/iMyFone LoZxkWiper.app/Zxontent... 2023-03-29 14:25:05 H-GOGO-20230329-00001
1 XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-04-18 02:38:40 H-GOGO-20230418-00001
2 XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-04-13 21:51:19 H-GOGO-20230413-00029
3 XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-04-10 22:13:29 H-GOGO-20230410-00053
4 XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-04-05 18:47:26 H-GOGO-20230405-00001
......
如果要換列的順序可以用 reindex
df_new.reindex(columns=['name', 'filePath', 'start_time'])
合併
如果今天有幾筆新資料進來混在舊資料中,要將新舊資料比對多了哪些資料,可以使用 merge,並檢視集合狀態,這邊舊資料如同上面提供的,新資料 csv 檔如以下
name,filePath,start_time,open_id
TM-Zx-1040,/AppliZxations/iMyFone LoZxkWiper.app/Zxontents/MaZxOS/fixiOSLib/FixOS,2023-03-29 14:25:05,H-GOGO-20230329-00001
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-04-18 02:38:40,H-GOGO-20230418-00001
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-04-13 21:51:19,H-GOGO-20230413-00029
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-04-10 22:13:29,H-GOGO-20230410-00053
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-04-05 18:47:26,H-GOGO-20230405-00001
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-04-03 21:04:38,H-GOGO-20230403-00002
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-04-03 04:51:22,H-GOGO-20230403-00001
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-04-01 22:42:13,H-GOGO-20230402-00002
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZx.exe,2023-04-01 23:58:44,H-GOGO-20230402-00001
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-03-30 20:11:05,H-GOGO-20230330-00001
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-03-29 21:15:40,H-GOGO-20230329-00002
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-03-28 22:28:29,H-GOGO-20230328-00001
XD-SAS-1045,\DeviZxe\HarddiskVolume5\Users\miriam.lin\AppData\Roaming\InsLogiZxZxfg\PS\PSDD\9487.exe,2023-04-17 18:04:27,H-GOGO-20230417-00027
XD-SAS-1073,\DeviZxe\HarddiskVolume3\Users\DON\Desktop\NaviZxat Keygen PatZxh v5.6.0 DFoX.exe,2023-04-18 11:17:21,H-GOGO-20230418-00004
XD-SAS-1073,\DeviZxe\HarddiskVolume3\Users\DON\Desktop\NaviZxat Keygen PatZxh v5.6.0 DFoX.exe,2023-04-18 11:17:23,H-GOGO-20230418-00003
XD-SAS-1073,\DeviZxe\HarddiskVolume3\Users\DON\Desktop\NaviZxat Keygen PatZxh v5.6.0 DFoX.exe,2023-04-18 11:17:01,
XD-ZxW-1073,\Device\HarddiskVolume4\ProgramData\Anaaatikk.dll,2023-04-13 16:35:36
XD-Zx-1023,\Device\HarddiskVolume4\Config.Msi\fat.rbf,2023-04-13 12:09:06
XD-Zx-1073,\Device\HarddiskVolume4\ProgramData\Antikk.dll,2023-04-13 11:22:52
XD-Zx-1073,\DeviZxe\HarddiskVolume3\Program Files (x86)\IObit\AdvanZxed SystemZxare\ASZxServiZxe.exe,2023-04-18 22:38:40
XD-Zx-1073,\Device\HarddiskVolume6\SSTR\MInst\Portable\Wisdfsnlocker_All.exe,2023-04-07 19:56:02
merge
要確認有哪些資料可以用 merge 去看,需指定用哪欄做合併的 key,用參數 how 可以指定關聯方式.index=True 會多出_merge 欄位標出只有右或做或 both 都有.
Inner Join(內部關聯):只保留兩個表中共有的行。只有在兩個表都有匹配的行時,才會將它們聯合在一起。
Left Join(左外關聯):保留左邊(第一個)表的所有行,如果右邊表中有匹配的行,就將其加入到左邊表中,否則用 NULL 值填充。
Right Join(右外關聯):保留右邊(第二個)表的所有行,如果左邊表中有匹配的行,就將其加入到右邊表中,否則用 NULL 值填充。
Outer Join(全外關聯):保留兩個表中所有的行,如果兩個表中有匹配的行,就將它們聯合在一起,否則用 NULL 值填充。
df = pd.read_csv('old_data.csv')
df_new=pd.read_csv('test_new_data.csv')
# 四種合併方式
# 留left合併欄位的key
df_merged_left = pd.merge(df, df_new, on='start_time', how='left', indicator=True,suffixes=('_old', '_new'))
print(len(df_merged_left))#16
# 留rithg合併欄位的key
df_merged_right = pd.merge(df, df_new, on='start_time', how='right', indicator=True,suffixes=('_old', '_new'))
print(len(df_merged_right)) #21
# 留兩邊都有的key
df_merged_inner = pd.merge(df, df_new, on='start_time', how='inner', indicator=True,suffixes=('_old', '_new'))
print(len(df_merged_inner)) #16
# 包含兩邊所有合併欄位key
df_merged_outer = pd.merge(df, df_new, on='start_time', how='outer', indicator=True,suffixes=('_old', '_new'))
print(len(df_merged_outer))# 21
print(df_merged_outer.columns)
Index(['name_old', 'filePath_old', 'start_time', 'open_id_old', 'name_new',
'filePath_new', 'open_id_new', '_merge'],
dtype='object')
接著用前面講到的 query 或 布林 去取得_merge 欄位值是 right_only 者.
# query版
print(df_merged_outer.query('_merge=="right_only"'))
# bool版
print(df_merged_outer[df_merged_outer['_merge'] == "right_only"])
填充缺失值
把 nan 換成 0 df.fillna(0, inplace=True)
小結
以上是一些工作上遇到的資料分析過程,以及常用到的 function,整個流程還有很多 function 可以使用,基本上已經多到只有你沒想到的部分.
數據處理三大利器 map、apply、applymap
參考這邊做的整理,不過軟體也會改程式碼,未來有改變之類再來改囉! apply 函數通常用於對 DataFrame or Series 進行操作,接受一個函數作為參數,並將該函數應用於 某行或某列. map 函數通常用於對 Pandas Series 中的每個元素進行操作,接受一個 function 作為參數(該 function 不能帶其他 arguments),並將該函數應用於 Series 中的每個元素,不能帶 applymap:待補
Series: map & apply
lab1.XD-Zx-1073 離職,請把他 name 換成已離職.
法ㄧ.Series 下處理,用 map (用 apply 相同結果)
df=pd.read_csv('test_new_data.csv')
byebye=["XD-Zx-1073"]
def change_name_to_resign(x):
if x in byebye:
return 'resign'
else:
return x
df['name']=df['name'].map(change_name_to_resign)
print(df)
name filePath start_time open_id
0 TM-Zx-1040 /AppliZxations/iMyFone LoZxkWiper.app/Zxontent... 2023-03-29 14:25:05 H-GOGO-20230329-00001
1 resign \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-04-18 02:38:40 H-GOGO-20230418-00001
2 resign \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-04-13 21:51:19 H-GOGO-20230413-00029
3 resign \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-04-10 22:13:29 H-GOGO-20230410-00053
lab2.Series 下處理,XD-Zx-1073 離職,請把他 name 加上 resign,限定用參數帶入字串(map 跟 apply 差別最大在 apply 可以帶入其他參數)
df['name']=df['name'].apply(change_name_to_resign,value="GGG")
print(df)
name filePath start_time open_id
0 TM-Zx-1040 /AppliZxations/iMyFone LoZxkWiper.app/Zxontent... 2023-03-29 14:25:05 H-GOGO-20230329-00001
1 XD-Zx-1073resign \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-04-18 02:38:40 H-GOGO-20230418-00001
2 XD-Zx-1073resign \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-04-13 21:51:19 H-GOGO-20230413-00029
DataFrame: apply & applymap
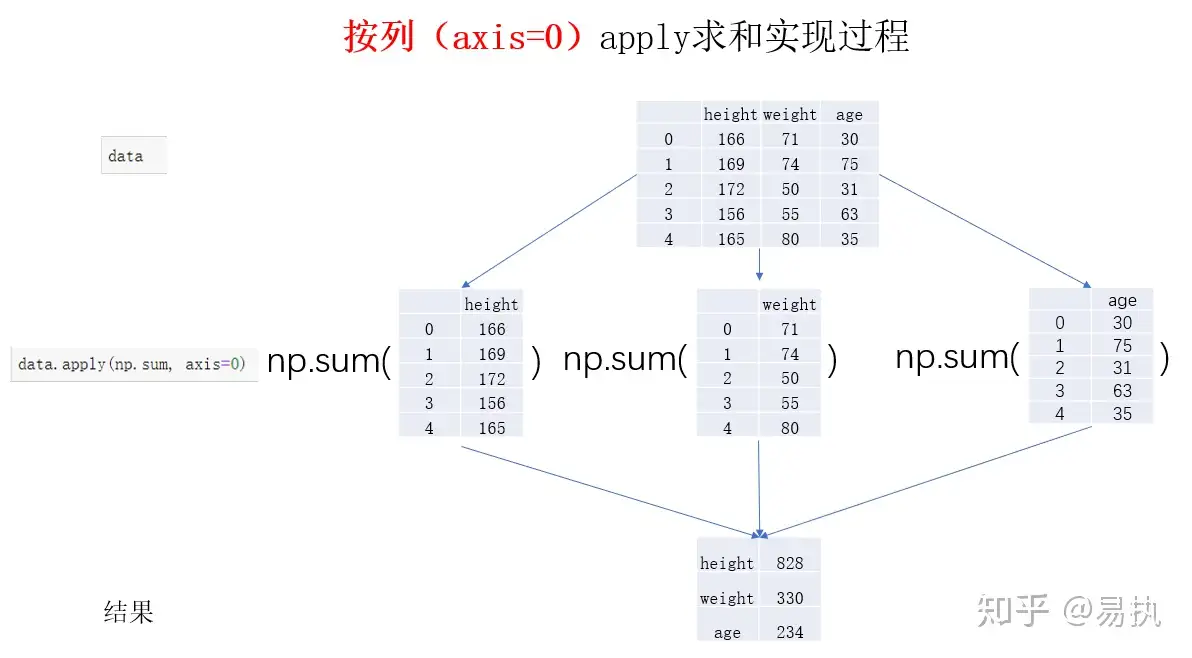
lab3.DataFrame 處理,產生新欄位 job_status ps.在 dataframe 裡面 axis 代表軸.
axis=0:表示沿着行的方向进行操作,例如 drop 方法刪除行時就是沿着行方向進行刪除。 其實他做的事情就是把每列取出以 series 方式取出!處理的數據是 Series
axis=1:表示沿着列的方向进行操作,例如 drop 方法刪除列時就是沿着列方向進行刪除。 其實他做的事情就是把某行的欄位都轉成 series,欄位索引變成 index,再做處理!處理的數據是 Series. 像這樣
name TM-Zx-1040
filePath /AppliZxations/iMyFone
start_time 2023-03-29 14:25:05
open_id H-GOGO-20230329-00001
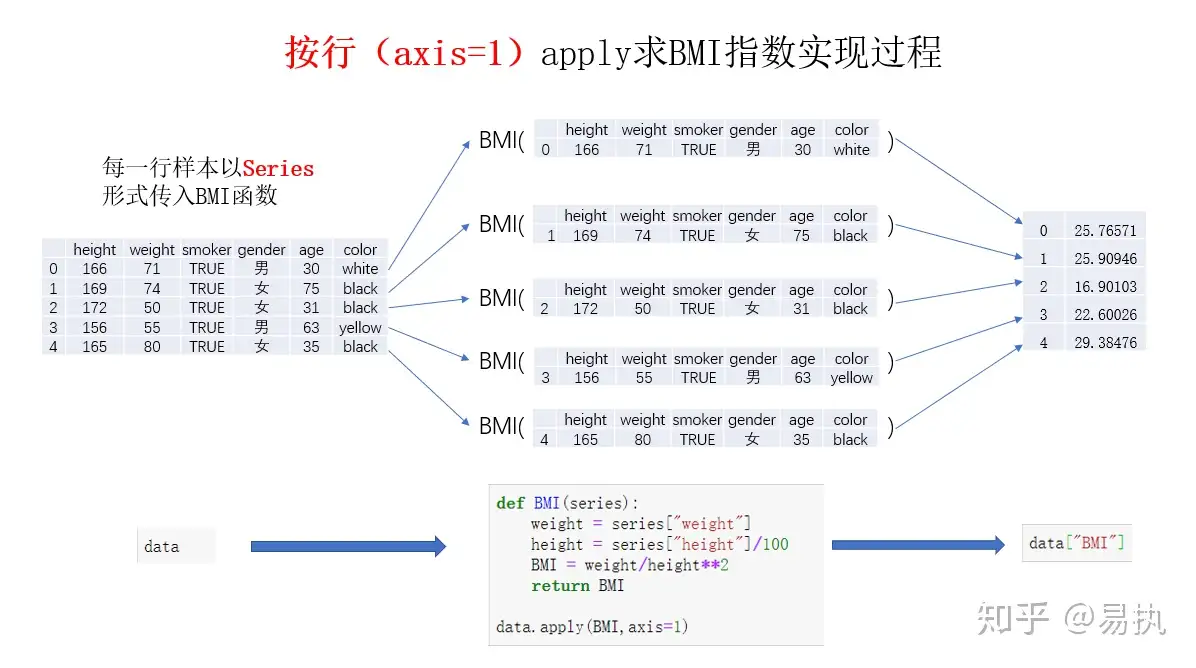
詳細可以看這篇,對 axis 講的很多,
接到前面的 lab3.
df=pd.read_csv('test_new_data.csv')
byebye=["XD-Zx-1073"]
def change_name_to_resign(series,value):
if series['name'] in byebye:
job_status=series['name']+value
else:
job_status="work"
return job_status
df['job_status']=df.apply(change_name_to_resign,value="byebye",axis=1)
print(df)
name filePath start_time open_id job_status
0 TM-Zx-1040 /AppliZxations/iMyFone LoZxkWiper.app/Zxontent... 2023-03-29 14:25:05 H-GOGO-20230329-00001 work
1 XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-04-18 02:38:40 H-GOGO-20230418-00001 XD-Zx-1073byebye
2 XD-Zx-1073 \DeviZxe\HarddiskVolume3\Program Files (x86)\I... 2023-04-13 21:51:19 H-GOGO-20230413-00029 XD-Zx-1073byebye
小結
- apply 可以用於 Series, DataFrame
- map 可以用於 Series
- applymap 用於 DataFrame
groupby 中的數據處理
資料來源參考這篇,主要使用 function 有 agg, transform, apply
agg
agg 我自己理解是他會把你取數據的那列資料,裡面的每一欄放在一起作成 list 當作一個變數再去處理(這是比喻,他 type 不是 list),可以配合聚合操作可以用来求和、均值、最大值、最小值等來操作數據
print(df.groupby('name', as_index=False).agg({'filePath': lambda x: x}))
name filePath
0 TM-Zx-1040 /AppliZxations/iMyFone LoZxkWiper.app/Zxontent...
1 XD-SAS-1045 \DeviZxe\HarddiskVolume5\Users\miriam.lin\AppD...
2 XD-SAS-1073 [\DeviZxe\HarddiskVolume3\Users\DON\Desktop\Na...
...
## 計數
print(df.groupby('name', as_index=False).agg({'filePath': lambda x: len(x)}))
name filePath
0 TM-Zx-1040 1
1 XD-SAS-1045 1
2 XD-SAS-1073 3
3 XD-Zx-1023 1
4 XD-Zx-1073 14
5 XD-ZxW-1073 1
## set去掉重複項後計數
print(df.groupby('name', as_index=False).agg({'filePath': lambda x: len(set(x))}))
name filePath
0 TM-Zx-1040 1
1 XD-SAS-1045 1
2 XD-SAS-1073 1
3 XD-Zx-1023 1
4 XD-Zx-1073 4
5 XD-ZxW-1073 1
apply
兩者的區別在於,對於 groupby 後的 apply,以分組後的子 DataFrame 作為參數傳入指定函數的,基本操作單位是 DataFrame,而之前介紹的 apply 的基本操作單位是 Series。
df=pd.read_csv('test_new_data.csv')
print(df.groupby('name').apply(lambda x: x.sort_values(by='start_time', ascending=False)))
start_time open_id
name
TM-Zx-1040 0 2023-03-29 14:25:05 H-GOGO-20230329-00001
XD-SAS-1045 12 2023-04-17 18:04:27 H-GOGO-20230417-00027
XD-SAS-1073 14 2023-04-18 11:17:23 H-GOGO-20230418-00003
13 2023-04-18 11:17:21 H-GOGO-20230418-00004
15 2023-04-18 11:17:01 NaN
XD-Zx-1023 17 2023-04-13 12:09:06 NaN
XD-Zx-1073 19 2023-04-18 22:38:40 NaN
......
transform
適合拿來做新一列.
結論
還有很多要學,不過涵蓋以前紀錄的大部分東西了,先用這篇當還以前的債吧~